:quality(75)/anh_dai_dien_52bea5089a.jpg)
Crawl là gì? Tìm hiểu chi tiết về quá trình thu thập dữ liệu trên web và vai trò của nó trong SEO
Trong thời đại số hóa ngày nay, việc biết cách các công cụ tìm kiếm như Google tìm thấy và lập chỉ mục các trang web là rất quan trọng. Quá trình này được gọi là Crawl, đóng vai trò then chốt trong việc đảm bảo trang web của bạn xuất hiện khi người dùng tìm kiếm thông tin. Hãy cùng tìm hiểu Crawl là gì, cách nó hoạt động và tại sao nó lại quan trọng đối với SEO.
Crawl là gì?
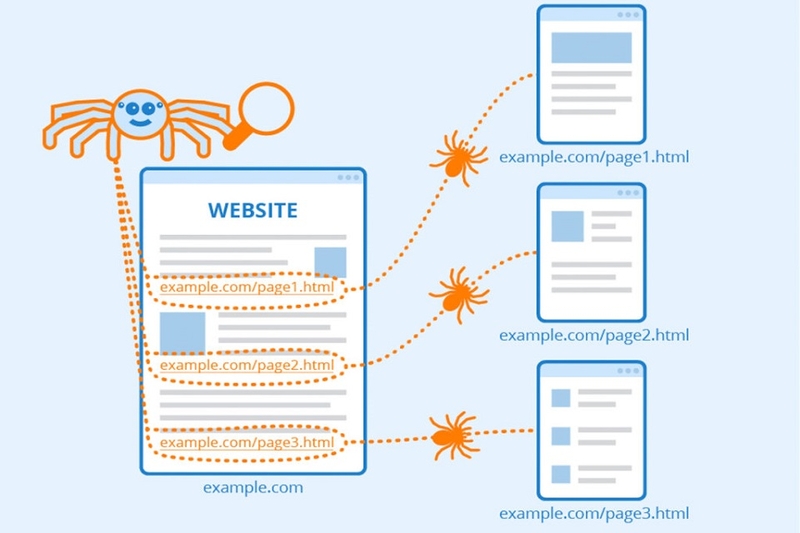
Crawl là gì? Clawl hay Crawl Web là quá trình thu thập thông tin tự động từ các trang web trên Internet thông qua các chương trình như Web Crawler (hay còn gọi là spider, robot hoặc bot). Các chương trình này gửi yêu cầu HTTP đến các trang web và phân tích phản hồi để trích xuất các tài nguyên như văn bản, hình ảnh, video hoặc âm thanh. Quá trình này bắt đầu từ một trang web nhất định và tiếp tục theo dõi các liên kết để thu thập dữ liệu từ các trang khác liên quan, sau đó lưu trữ trong cơ sở dữ liệu để phục vụ các công cụ tìm kiếm hoặc các mục đích nghiên cứu khác.
Crawl Web được ứng dụng rộng rãi trong các lĩnh vực như nghiên cứu thị trường, phân tích dữ liệu và đánh giá hiệu quả của các chiến dịch tiếp thị kỹ thuật số. Tuy nhiên, việc sử dụng công nghệ này cần được cân nhắc kỹ lưỡng để tránh vi phạm quyền riêng tư và bản quyền. Do đó, các hoạt động Crawl Web phải tuân thủ các quy định pháp lý và chuẩn mực đạo đức.
Vai trò của Crawl Web

Sau khi tìm hiểu Crawl là gì, tiếp theo đây, chúng ta sẽ cùng khám phá vì sao quá trình này lại quan trọng đến vậy đối với việc tìm kiếm thông tin trên mạng. Internet là một kho tàng thông tin khổng lồ với hàng tỷ trang web, trong đó có hàng triệu trang mới được tạo ra mỗi ngày. Để tìm kiếm thông tin chính xác và nhanh chóng từ khối lượng dữ liệu khổng lồ này, Crawl Web trở thành một công cụ không thể thiếu. Thay vì tìm kiếm thủ công tốn nhiều thời gian và công sức, các chương trình Crawl tự động giúp thu thập dữ liệu từ nhiều nguồn khác nhau một cách nhanh chóng.
Lợi ích của Crawl Web trong việc tìm kiếm thông tin

Crawl Web giúp thu thập thông tin từ hàng triệu trang web, từ phổ biến đến chuyên ngành ít được biết đến. Nhờ khả năng thu thập nhanh và liên tục, nó cung cấp cho người dùng nguồn dữ liệu đa dạng, đảm bảo thông tin luôn được cập nhật mới nhất từ nhiều lĩnh vực như giải trí, khoa học và công nghệ.
Cập nhật thông tin và tối ưu kết quả tìm kiếm
Với sự phát triển không ngừng của các trang web, việc cập nhật thông tin liên tục là thiết yếu. Crawl Web giúp công cụ tìm kiếm duy trì dữ liệu mới nhất, cung cấp kết quả chính xác và phù hợp cho người dùng thông qua các thuật toán phân tích phức tạp, tiết kiệm thời gian tìm kiếm.
Ứng dụng trong nghiên cứu và tiếp thị
Không chỉ dừng lại ở việc hỗ trợ tìm kiếm, Crawl Web còn cung cấp dữ liệu phong phú cho các nhà nghiên cứu và các chuyên gia tiếp thị. Dữ liệu thu thập từ quá trình Crawl là cơ sở để phân tích xu hướng, đánh giá chiến dịch tiếp thị kỹ thuật số và hiểu rõ hơn về thị trường mục tiêu.
Như vậy, Crawl Web đóng vai trò quan trọng trong việc tìm kiếm và cập nhật thông tin trên Internet. Nhờ khả năng thu thập dữ liệu rộng rãi và liên tục, nó không chỉ giúp tối ưu hóa trải nghiệm tìm kiếm mà còn mở ra nhiều cơ hội phân tích dữ liệu cho các ngành công nghiệp khác nhau.
Cách hoạt động của Crawl Web
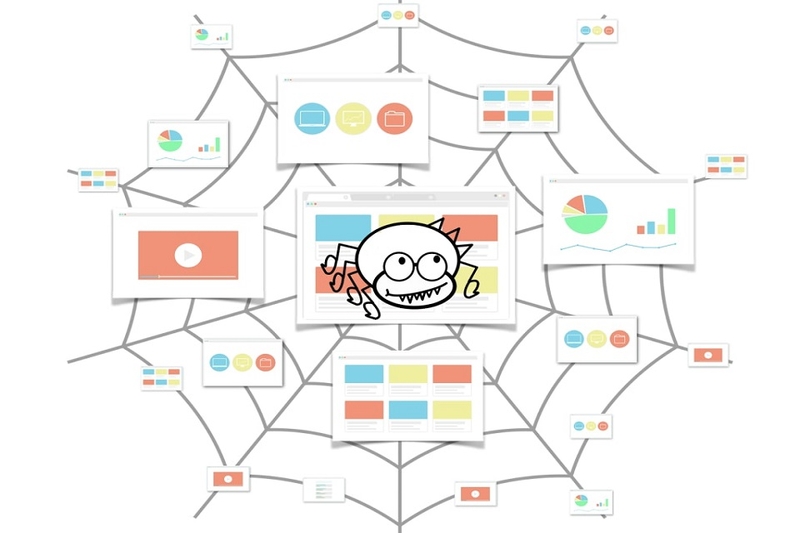
Crawl Web là quá trình tự động thu thập dữ liệu từ các trang web bằng cách sử dụng các chương trình máy tính gọi là Web Crawler. Quá trình này giúp thu thập thông tin từ Internet, phục vụ cho việc tìm kiếm, phân tích dữ liệu và tối ưu hóa kết quả tìm kiếm. Dưới đây là cách Crawl Web hoạt động chi tiết.
Quá trình tải xuống các trang web và phân tích nội dung
Quá trình thu thập dữ liệu bắt đầu từ việc tìm kiếm các trang web và quyết định tải về những trang phù hợp. Các bước chính bao gồm:
- Tìm kiếm trang web: Web Crawler sẽ tìm kiếm các trang web thông qua công cụ tìm kiếm hoặc các nguồn liên quan để xác định những trang chứa thông tin cần thiết.
- Xác định độ ưu tiên: Các trang web được đánh giá dựa trên nhiều tiêu chí như độ quan trọng, độ tin cậy, độ phổ biến và tần suất cập nhật.
- Đánh giá độ sâu của trang web: Độ sâu của một trang web đề cập đến số lượng liên kết nội bộ mà Crawler cần theo dõi để thu thập thông tin. Độ sâu thường được giới hạn để tối ưu hóa việc thu thập.
- Lựa chọn trang web để tải về: Dựa vào các tiêu chí đánh giá, Crawler sẽ quyết định những trang nào cần được thu thập dữ liệu.
- Tải về và lưu trữ thông tin: Sau khi lựa chọn, Web Crawler sẽ tải về các trang web và lưu trữ thông tin như tiêu đề, nội dung, liên kết và các yếu tố khác.
- Duy trì và cập nhật dữ liệu: Web Crawler sẽ liên tục duy trì dữ liệu đã thu thập và cập nhật thông tin mới từ các trang web khi cần.
Phân tích cấu trúc trang web
Để thu thập thông tin chính xác, Web Crawler cần hiểu cấu trúc của trang web. Quá trình này bao gồm:
- Phân tích cấu trúc HTML: Crawler phân tích các yếu tố HTML như tiêu đề, liên kết và nội dung để xác định các thông tin quan trọng.
- Phân tích cấu trúc CSS: Nếu trang web sử dụng CSS để định dạng, Crawler sẽ cần phân tích các lớp và kiểu định dạng để hiểu cách bố trí và hiển thị các yếu tố.
- Phân tích cấu trúc JavaScript: Nếu trang sử dụng JavaScript để tạo ra các hiệu ứng động hoặc thay đổi nội dung, Crawler cần phân tích mã JavaScript để hiểu cách trang web hoạt động.
- Xác định liên kết giữa các trang web: Crawler theo dõi các liên kết giữa các trang web để khám phá và thu thập thêm dữ liệu từ các trang liên quan.
- Đánh giá độ ưu tiên của các phần tử trên trang: Crawler sẽ xác định phần tử nào trên trang cần được ưu tiên thu thập trước, dựa trên tầm quan trọng và giá trị của thông tin.
Lưu trữ và phân tích dữ liệu
Sau khi thu thập, dữ liệu cần được xử lý và lưu trữ một cách hiệu quả để phục vụ cho các mục đích nghiên cứu, phân tích hoặc sử dụng trong kinh doanh. Các bước bao gồm:
- Lưu trữ dữ liệu: Dữ liệu thu thập được lưu vào cơ sở dữ liệu hoặc các hệ thống lưu trữ khác để dễ dàng quản lý và truy xuất.
- Tiền xử lý dữ liệu: Trước khi phân tích, dữ liệu cần được làm sạch, loại bỏ những thông tin không cần thiết hoặc trùng lặp.
- Phân tích cú pháp và nội dung: Crawler sẽ phân tích ngữ pháp và cấu trúc nội dung để xác định thông tin quan trọng như tiêu đề, liên kết và nội dung chính.
- Trích xuất thông tin: Thông tin quan trọng được trích xuất từ dữ liệu để sử dụng cho mục đích cụ thể, như nghiên cứu thị trường hoặc tối ưu hóa chiến dịch tiếp thị.
- Phân tích dữ liệu: Dữ liệu được phân tích bằng các công cụ như khai thác dữ liệu, học máy, hoặc phân tích văn bản để đưa ra các dự đoán hoặc kết luận.
Các công cụ Crawl phổ biến hiện nay

Bạn đã biết Crawl là gì rồi và công cụ Crawl là quá trình mà các chương trình như bot hoặc spider tự động thu thập dữ liệu từ các trang web, tương tự như cách một con nhện giăng tơ từ trang này sang trang khác, tạo nên một mạng lưới liên kết khổng lồ. Những dữ liệu được thu thập sẽ giúp tạo nên cơ sở dữ liệu cho các công cụ tìm kiếm, từ đó cung cấp thông tin cho người dùng. Dưới đây là một số công cụ Crawl phổ biến và cách chúng hoạt động:
Googlebot của Google

Googlebot là Web Crawler chính của Google, được thiết kế để quét và thu thập dữ liệu từ các trang web nhằm phục vụ việc lập chỉ mục (indexing) cho kết quả tìm kiếm của Google. Những lợi ích khi sử dụng Googlebot gồm có:
- Đảm bảo trang web được hiển thị trên Google: Khi Googlebot quét trang, dữ liệu sẽ được lưu vào cơ sở dữ liệu của Google để hiển thị trong kết quả tìm kiếm.
- Kiểm tra tính tương thích SEO: Googlebot thu thập thông tin về tiêu đề, nội dung, liên kết và các yếu tố khác, hỗ trợ kiểm tra và cải thiện tính tương thích SEO của trang web.
- Theo dõi sự thay đổi của trang web: Googlebot liên tục cập nhật dữ liệu để đảm bảo thông tin trang web luôn mới và chính xác.
Bingbot của Bing

Bingbot là công cụ Crawler của Bing, có chức năng tương tự Googlebot nhưng phục vụ cho công cụ tìm kiếm Bing. Bingbot sẽ:
- Thu thập dữ liệu từ trang web: Bingbot quét các trang web để thu thập tiêu đề, nội dung và liên kết, sau đó lưu trữ thông tin vào cơ sở dữ liệu của Bing.
- Cập nhật thông tin trang web: Nó cũng thường xuyên quét lại các trang đã thu thập để cập nhật những thay đổi, đảm bảo kết quả tìm kiếm luôn chính xác.
Yandexbot của Yandex

Yandexbot là công cụ Crawler của Yandex, một công cụ tìm kiếm hàng đầu của Nga. Nó hoạt động theo các nguyên tắc tương tự như Googlebot và Bingbot, thu thập và cập nhật dữ liệu cho hệ thống tìm kiếm của Yandex. Yandexbot tập trung vào các thị trường như Nga và các quốc gia lân cận, với khả năng tối ưu hóa nội dung dành cho người dùng tại đây.
Naverbot của Naver

Naverbot là công cụ Crawl của Naver, công cụ tìm kiếm phổ biến nhất tại Hàn Quốc. Giống như các công cụ khác, Naverbot thu thập thông tin từ các trang web để cung cấp kết quả tìm kiếm chính xác và cập nhật cho người dùng. Naverbot được tối ưu hóa cho ngôn ngữ và nhu cầu tìm kiếm của người Hàn Quốc, tạo ra sự khác biệt lớn trong hệ thống tìm kiếm của Naver.
Tạm kết
Hy vọng qua nội dung bài viết này, bạn đã hiểu rõ hơn về Crawl là gì, quá trình Crawl Web và vai trò quan trọng của nó trong SEO. Từ việc tự động thu thập dữ liệu đến việc hỗ trợ tối ưu hóa kết quả tìm kiếm, Crawl Web đóng góp to lớn trong việc duy trì và cập nhật thông tin trên các công cụ tìm kiếm. Bằng cách áp dụng đúng cách, bạn không chỉ có thể nâng cao thứ hạng của trang web mà còn tối ưu trải nghiệm người dùng một cách hiệu quả. Hãy luôn cân nhắc tuân thủ các quy định và chuẩn mực đạo đức khi sử dụng công nghệ này để đảm bảo sự phát triển bền vững.
Nếu bạn đang tìm kiếm một chiếc laptop văn phòng bền bỉ và hiệu quả, hãy đến ngay FPT Shop. Tại đây có nhiều lựa chọn từ các thương hiệu hàng đầu với giá ưu đãi và hỗ trợ trả góp linh hoạt dành cho bạn:
Xem thêm
:quality(75)/2024_2_6_638428544489203417_meta-tag-1-1.jpg)
:quality(75)/2023_6_6_638216670907570789_ajax-la-gi.jpg)
:quality(75)/2024_3_20_638465407708095173_google-my-business.jpeg)
:quality(75)/2023_12_29_638394668389341151_www-la-gi-nen.png)
:quality(75)/2023_12_31_638396520115922784_clickbait-la-gi-kham-pha-cach-thuc-trien-khai-clickbait-hieu-qua-cho-seo-marketing-0.jpg)
:quality(75)/2024_2_3_638425769817114675_anh-dai-dien.jpg)