:quality(75)/2024_2_7_638429026556788883_mapreduce-1-1.jpg)
Mapreduce là gì? Học ngay những kiến thức quan trọng về mô hình Mapreduce
Mapreduce được xem là một trong những thành phần thiết yếu góp phần nâng cao sức mạnh của Hadoop. Loại framework này đã được sử dụng rộng rãi trong lĩnh vực lập trình hiện đại. Vậy Mapreduce có những đặc điểm gì? Các hàm chính do nó thực thi ra sao? Mời bạn cùng FPT Shop theo dõi bài viết bên dưới để biết đáp án.
Định nghĩa Mapreduce là gì?
MapReduce là mô hình lập trình và công cụ tính toán song song chủ yếu được sử dụng để xử lý, phân tích lượng dữ liệu lớn. Mô hình này được phát triển bởi Google và sau đó được Apache Hadoop đã triển khai và biến nó trở nên phổ biến hơn. MapReduce chia quá trình xử lý dữ liệu thành hai phần chính là Map và Reduce.

Trong quá trình Map, dữ liệu đầu vào được chia nhỏ và xử lý bởi nhiều máy tính song song để tạo ra các cặp key - value tương ứng. Sau đó, các cặp key - value này được sắp xếp và gom nhóm theo key để chuẩn bị cho quá trình Reduce.
Trong quá trình Reduce, dữ liệu từ quá trình Map được tổng hợp, xử lý và kết hợp để tạo ra kết quả cuối cùng. Quá trình này cho phép xử lý song song trên nhiều máy tính và hoạt động hiệu quả với dữ liệu lớn.
Tổng hợp các hàm chính của MapReduce
MapReduce có hai hàm chính gồm Map và Reduce, những đặc điểm cơ bản của mỗi hàm bao gồm:
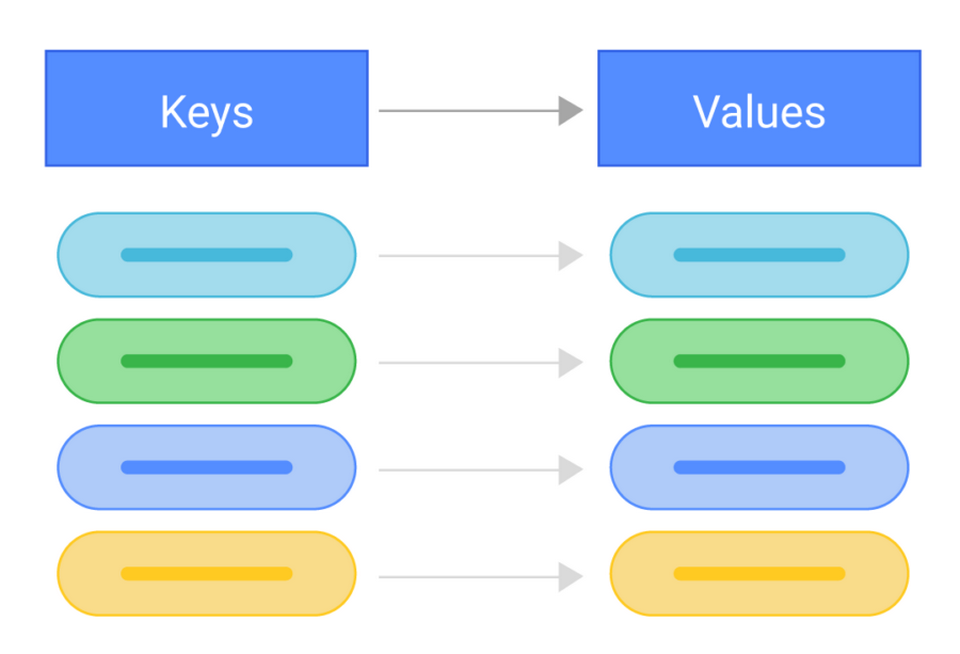
- Hàm Map: Đây là hàm đầu tiên được áp dụng trong quá trình MapReduce. Hàm Map nhận vào một cặp key - value từ dữ liệu nguồn và thực hiện xử lý trên cặp key - value này để tạo ra các cặp key - value mới. Các kết quả tạo ra từ hàm Map được sắp xếp theo key, để chuẩn bị cho quá trình Reduce.
- Hàm Reduce: Đây là hàm thứ hai trong quá trình MapReduce. Hàm Reduce nhận các cặp key - value đã được sắp xếp từ quá trình Map và thực hiện các phép xử lý gộp, tổng hợp, tính toán hoặc phân loại để tạo ra kết quả cuối cùng.
Ngoài hai hàm chính trên, trong quá trình MapReduce còn có hàm Partition, Combiner và Shuffle được sử dụng để tối ưu quá trình xử lý dữ liệu.
- Hàm Partition: Phân vùng dữ liệu sau pha Map để phân phối dữ liệu tới các task của Reduce.
- Combiner: Hàm tối ưu để thực hiện các xử lý trên dữ liệu ngay tại máy Map trước khi chuyển qua máy Reduce.
- Shuffle: Quá trình trao đổi và sắp xếp dữ liệu giữa Map và Reduce.
Sự kết hợp của các hàm này tạo nên quy trình xử lý phân tán, song song và hiệu quả cho việc xử lý và phân tích dữ liệu lớn trong môi trường phân tán.
Những ưu điểm nổi bật của MapReduce
Những ưu điểm dưới đây đã làm cho MapReduce trở thành công cụ mạnh mẽ trong việc xử lý và phân tích dữ liệu lớn từ các ứng dụng thương mại và nghiên cứu.

- Xử lý dữ liệu lớn: MapReduce được thiết kế để xử lý và phân tích dữ liệu lớn bằng một cách hiệu quả, cho phép các công ty và tổ chức xử lý các dữ liệu có kích thước rất lớn mà trước đây chưa được thực hiện được.
- Tính mở rộng: MapReduce có khả năng mở rộng ngang, điều này có nghĩa là nó có thể chạy trên nhiều bài hát máy tính độc lập, giúp tăng tốc độ xử lý và xử lý dữ liệu đạt hiệu quả cao nhất.
- Dung sai Tool: Hệ thống Map Giảm khả năng chịu lỗi tốt, tức là nếu có một hoặc một số nút xử lý dữ liệu gặp sự cố, hệ thống vẫn có khả năng hoàn thành công việc một cách an toàn.
- Phân tích dữ liệu: Quá trình phân tích bài hát dữ liệu giữa các tác vụ bản đồ và sắp xếp theo khóa làm cho quá trình xử lý luôn trở nên hiệu quả và tối ưu.
- Hỗ trợ nhiều loại dữ liệu: MapReduce có khả năng xử lý một loạt các loại dữ liệu khác nhau, bao gồm bao cấu trúc và bất kỳ cấu trúc nào, từ văn bản đến hình ảnh và video.

Ngoài ra, MapReduce không giới hạn sử dụng trên một ngôn ngữ lập trình cụ thể. Trong thực tế, MapReduce có thể được triển khai trên nhiều ngôn ngữ lập trình khác nhau như Java, Python, C++ và nhiều ngôn ngữ khác thông qua các framework và thư viện hỗ trợ.
Ví dụ, Apache Hadoop là một trong những mô hình triển khai MapReduce phổ biến nhất hiện nay. Nền tảng được hỗ trợ bởi các ngôn ngữ như Java, Python, và Ruby. Apache Hadoop thiết kế để hỗ trợ việc triển khai các chương trình MapReduce viết bằng các ngôn ngữ lập trình khác nhau thông qua các giao diện API và thư viện hỗ trợ.
Tùy thuộc vào môi trường, yêu cầu cụ thể và sở thích ngôn ngữ lập trình, MapReduce có khả năng được triển khai trên nhiều ngôn ngữ lập trình khác nhau để đáp ứng nhu cầu cần thiết của mỗi ứng dụng.
Tìm hiểu nguyên tắc hoạt động của MapReduce
MapReduce hoạt động theo nguyên tắc chia nhỏ công việc và thực hiện xử lý song song trên nhiều máy tính. Dưới đây giới thiệu chi tiết về nguyên tắc hoạt động của MapReduce:

- Chia dữ liệu: Trước hết, dữ liệu đầu vào sẽ được chia nhỏ thành các phần nhỏ hơn để phân tán trên nhiều máy tính. Điều này giúp tạo điều kiện để xử lý song song và tối ưu việc tải cho mỗi máy tính tham gia quá trình xử lý.
- Quá trình Map: Mỗi máy tính sẽ thực hiện quá trình Map trên các phần dữ liệu mà nó đảm nhận. Trong quá trình Map, các phần dữ liệu được xử lý để tạo ra các cặp key - value tương ứng với những thông tin cần thiết cho việc phân tích và xử lý tiếp theo.
- Phân phối và sắp xếp: Sau khi quá trình Map hoàn tất, các cặp key - value được phân phối tới các máy tính khác nhau dựa trên key và sắp xếp để chuẩn bị cho quá trình Reduce.
- Quá trình Reduce: Các máy tính tiếp tục thực hiện quá trình Reduce, trong đó các cặp key - value được tổng hợp, xử lý và tính toán để tạo ra kết quả cuối cùng của quá trình MapReduce.
- Kết quả cuối cùng: Kết quả từ quá trình Reduce sẽ là kết quả cuối cùng của quá trình MapReduce và có thể được lưu trữ hoặc sử dụng cho mục đích phân tích hoặc hiển thị.
Qua các bước trên, MapReduce cho phép xử lý dữ liệu lớn một cách hiệu quả và tận dụng được sức mạnh của việc thực hiện xử lý song song trên nhiều máy tính. Từ đó mà hệ thống sẽ nhanh chóng đạt được kết quả mong muốn.
Các luồng dữ liệu trên nền tảng MapReduce
MapReduce sử dụng mô hình luồng dữ liệu để xử lý dữ liệu và thực hiện các pha chính của quá trình. Luồng dữ liệu nền tảng của MapReduce bao gồm các bước chính sau:

- Đầu vào (Input): Dữ liệu đầu vào được chia nhỏ thành các phần nhỏ gọi là "input splits". Mỗi input split chứa một phần của dữ liệu và được xử lý độc lập trên các máy tính khác nhau.
- Map Phase (Giai đoạn Map): Trong giai đoạn này, dữ liệu từ các input splits được ánh xạ sang các cặp key - value thông qua hàm Map. Kết quả của giai đoạn Map là tập hợp các cặp key-value tương ứng với các giá trị đã được xử lý.
- Phân phối (Shuffle): Kết quả từ giai đoạn Map được phân phối đến các máy tính khác nhau dựa trên key của các cặp key - value. Điều này tạo điều kiện cho việc tổ chức và chuẩn bị dữ liệu cho giai đoạn Reduce.
- Reduce Phase (Giai đoạn Reduce): Trong giai đoạn này, các cặp key - value có cùng key được tổng hợp và xử lý trên các máy tính khác nhau, tạo ra kết quả cuối cùng.
- Kết quả (Output): Kết quả từ giai đoạn Reduce là kết quả cuối cùng của quá trình MapReduce được lưu trữ hoặc sử dụng cho mục đích tiếp theo.
Qua các bước trên, MapReduce tận dụng luồng dữ liệu để xử lý dữ liệu lớn một cách hiệu quả và song song trên các máy tính khác nhau trong một cụm xử lý.
Ví dụ cụ thể về hoạt động của MapReduce
Một ví dụ cụ thể về công cụ có thể kích hoạt MapReduce là Apache Hadoop. Hadoop là dạng framework mã nguồn mở được thiết kế để xử lý và lưu trữ dữ liệu lớn trên các cụm máy tính phân tán. Nền tảng cung cấp mô hình lập trình cho việc triển khai MapReduce.
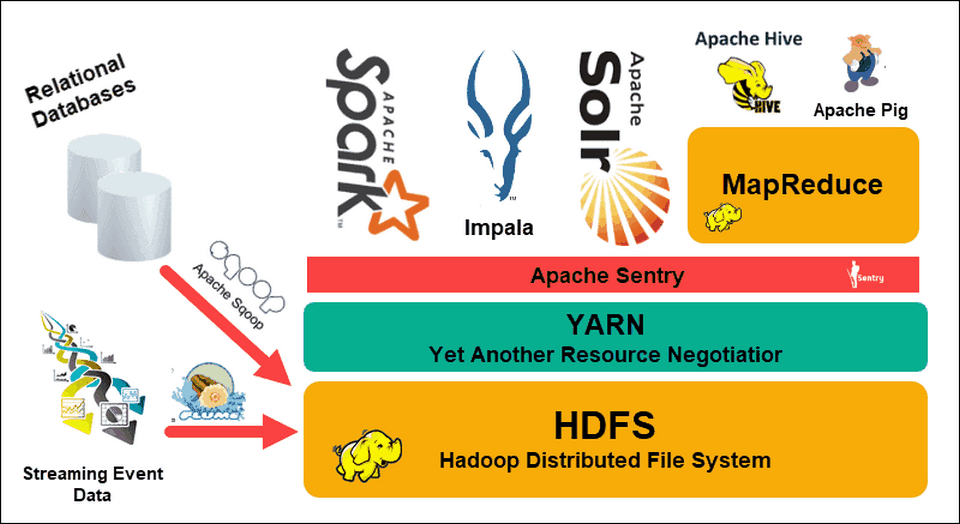
Hadoop cung cấp các thành phần như Hadoop Distributed File System (HDFS) để lưu trữ dữ liệu và YARN (Yet Another Resource Negotiator) để quản lý việc triển khai các tác vụ MapReduce trên một cụm máy tính phân tán.
Công cụ này cho phép người dùng triển khai và chạy các chương trình MapReduce viết bằng Java, Python hoặc một số ngôn ngữ khác thông qua các giao diện API và thư viện hỗ trợ. Hadoop cung cấp giải pháp xử lý lượng dữ liệu lớn bằng cách tận dụng khả năng xử lý song song trên các máy tính trong một cụm, ví dụ như công cụ kích hoạt MapReduce.
Những công việc có thể sử dụng MapReduce là gì?
MapReduce có thể được sử dụng cho nhiều công việc xử lý dữ liệu lớn, bao gồm:

- Đếm từ: Quá trình đếm từ trong văn bản là một trong những công việc cơ bản nhất mà MapReduce có thể thực hiện. Việc này giúp phân tích tần suất xuất hiện của từ trong một tập dữ liệu lớn.
- Log xử lý: Xử lý và phân tích logs từ các hệ thống máy chủ và ứng dụng để tìm kiếm thông tin quan trọng như lỗi, cảnh báo hoặc thống kê về hoạt động hệ thống.
- Xử lý dữ liệu nguyên văn bản lớn: Phân tích và xử lý dữ liệu nguyên văn bản lớn như bài báo, sách điện tử, tài liệu khoa học để trích xuất thông tin cần thiết.
- Tính toán thống kê: Tính toán thống kê trên dữ liệu lớn như max, min, trung bình, độ lệch chuẩn, và phân phối dữ liệu.
- Định vị vị trí: Phân tích dữ liệu địa lý hoặc GPS để xác định mô hình di chuyển, thói quen sử dụng và dự đoán vị trí tương lai.
- Xử lý dữ liệu clickstream: Phân tích dữ liệu clickstream từ trang web hoặc ứng dụng để hiểu hành vi người dùng, tối ưu hóa trải nghiệm và quảng cáo.
Tạm kết
Qua đây, hy vọng bạn đọc đã hiểu đầy đủ thông tin về Mapreduce và cách ứng dụng công cụ hiệu quả. Nền tảng sẽ mang đến rất nhiều thông tin hữu ích trong việc nâng cao kỹ năng và kinh nghiệm lập trình.
Xem thêm:
- ACLS là gì? Tìm hiểu vai trò đặc biệt của ACLS trong quá trình bảo mật hệ thống
- Khám phá giao thức IPSec với nguyên lý hoạt động và những kiến thức quan trọng
FPT Shop cung cấp rất nhiều dòng thiết bị điện tử chất lượng đến từ các thương hiệu công nghệ nổi tiếng. Nếu bạn đang muốn tìm kiếm công cụ phục vụ quá trình học tập hoặc làm việc thì hãy ghé thăm cửa hàng. Bạn sẽ nhận được rất nhiều chương trình ưu đãi, hậu mãi tuyệt vời tại đây!