:quality(75)/2023_11_18_638359222109453814_web-scraping-la-gi-1-1.jpg)
Giới thiệu về đặc điểm và cách ứng dụng Web Scraping trong cuộc sống hiện nay
Web Scraping ra đời trong bối cảnh Internet bùng nổ, đặc biệt là nhu cầu truy xuất dữ liệu của người dùng. Nhờ sự xuất hiện của công nghệ này đã góp phần nâng cao hiệu suất tìm kiếm thông tin hiệu quả. Vậy tính ứng dụng của Web Scraping là gì? Mời bạn cùng FPT Shop đi tìm đáp án thông qua những chia sẻ thú vị dưới đây!
Giải thích Web Scraping là gì?
Web Scraping là quá trình tự động thu thập dữ liệu từ các trang web công cộng và lưu trữ chúng để phân tích hoặc sử dụng theo cách khác. Quá trình này thường được thực hiện bằng cách sử dụng các chương trình máy tính hoặc bot để trích xuất thông tin từ trang web theo một cấu trúc được xác định trước.
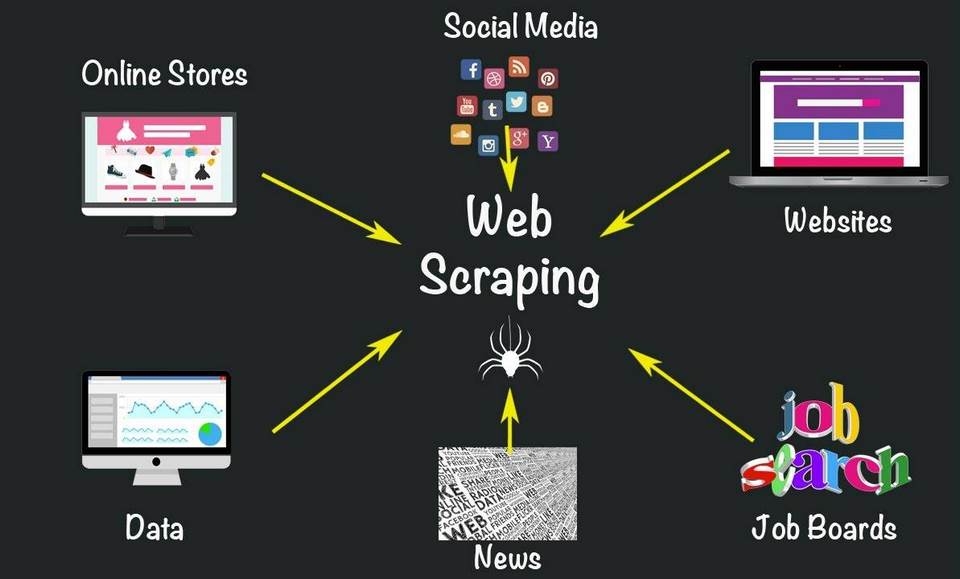
Dữ liệu thu thập từ Web Scraping được dùng để nghiên cứu thị trường, giám sát giá cả, phân tích thông tin hoặc tạo nội dung mới. Tuy nhiên, việc triển khai Web Scraping cần phải tuân thủ các quy định và điều kiện sử dụng của trang web mà bạn đang thu thập dữ liệu từ.
Một số trang web có thể cấm việc Web Scraping hoặc yêu cầu sự "chấp thuận" trước khi thu thập dữ liệu từ họ. Nếu không tuân thủ các quy định này, bạn có thể vi phạm luật bản quyền hoặc chính sách của trang web đó.
Tìm hiểu mục đích sử dụng của Web Scraping
Web Scraping có thể được sử dụng để nhiều mục đích khác nhau, bao gồm:
- Nghiên cứu thị trường: Thu thập dữ liệu từ các trang web thương mại điện tử để phân tích xu hướng mua sắm, đánh giá cạnh tranh và xác định giá cả.
- Dự báo và phân tích dữ liệu: Sử dụng dữ liệu từ Web Scraping để phân tích và dự đoán xu hướng thị trường, dự báo kết quả kinh doanh và tìm ra thông tin cần thiết cho việc ra quyết định.
- Giám sát thông tin: Theo dõi các thông tin cập nhật trên các trang web để cập nhật thông tin về sự kiện, tin tức, hoặc dữ liệu thay đổi về sản phẩm và dịch vụ.
- Tạo nội dung mới: Thu thập dữ liệu để tạo nội dung mới hoặc cập nhật thông tin trên trang web của mình.
- Thảo luận và nghiên cứu: Phân tích văn bản trên internet để tìm kiếm ý kiến, suy nghĩ hoặc tình hình lược đồ phản ứng xã hội đối với một sự kiện hoặc chủ đề cụ thể.
Những lĩnh vực phổ biến sử dụng Web Scraping
Thông qua những tài liệu thống kê của Linkedin tại Mỹ cho thấy Web Scraping được sử dụng trong 54 lĩnh vực khác nhau. Người dùng có thể cập nhật 10 lĩnh vực sử dụng công cụ này phổ biến nhất phải kể đến là:

- Phần mềm máy tính (22%)
- Công nghệ thông tin và dịch vụ (21%)
- Dịch vụ tài chính (12%)
- Internet (11%)
- Tiếp thị và quảng cáo (5%)
- Bảo mật máy tính & mạng (3%)
- Bảo hiểm (2%)
- Ngân hàng (2%)
- Tư vấn quản lý (2%)
- Truyền thông trực tuyến (2%).
Tổng hợp những loại Web Scraping phổ biến
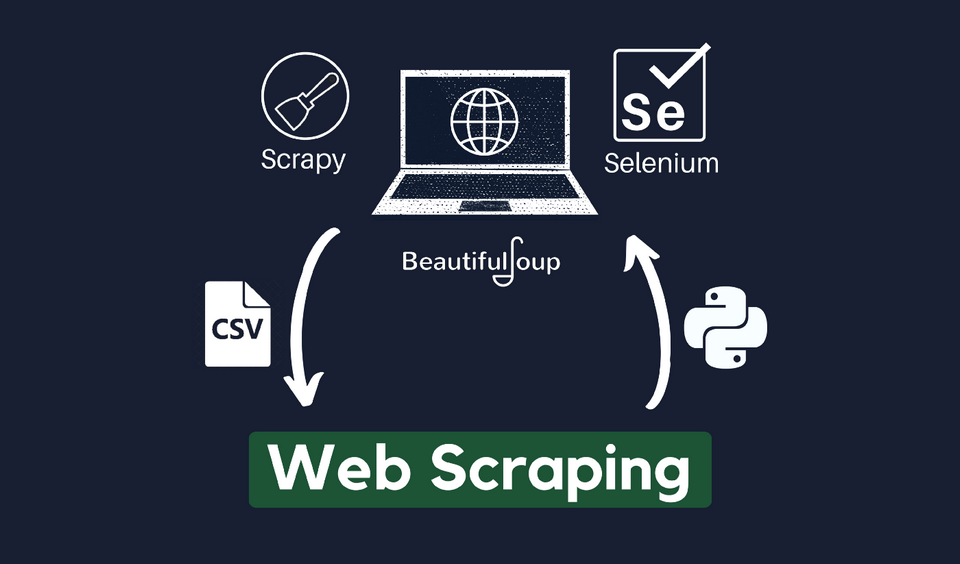
Trên thực tế có nhiều phương pháp và kỹ thuật khác nhau được sử dụng trong Web Scraping. Dưới đây là một số loại Web Scraping phổ biến:
Parsing HTML
Trong phương pháp này, các thư viện như Beautiful Soup hoặc XML được sử dụng để phân tích HTML của trang web và trích xuất dữ liệu cụ thể dựa trên các thẻ HTML, lớp và id.
Sử dụng API
Một số trang web cung cấp API (Giao diện lập trình ứng dụng) cho phép truy cập dữ liệu một cách cấu trúc và có thể được sử dụng để thu thập dữ liệu một cách dễ dàng, không cần phải thông qua Web Scraping truyền thống.
Sử dụng Selenium
Selenium là một công cụ tự động hóa trình duyệt web, cho phép bạn tương tác với trang web và trích xuất dữ liệu thông qua việc mô phỏng các hành động người dùng như click chuột, điền form, etc.
Sử dụng Scraping Frameworks
Có nhiều framework như Scrapy, Puppeteer và Cheerio được sử dụng để phát triển hoặc thực hiện các công việc liên quan đến Web Scraping. Một số công cụ tự động hóa được sử dụng để lập kế hoạch và thực hiện các thao tác Web Scraping tự động. Các tiện ích giúp thu thập dữ liệu một cách liên tục và ổn định.
Nguyên tắc hoạt động của Web Scraper
Web scraper hoạt động bằng cách tải xuống và phân tích cấu trúc trang web để trích xuất dữ liệu cụ thể theo yêu cầu của người dùng. Dưới đây là cách hoạt động cơ bản của một web scraper:
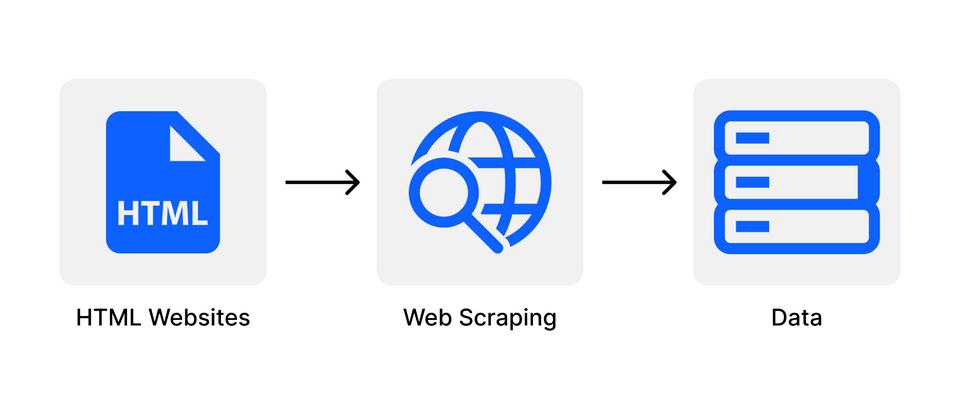
- Lập kế hoạch và xác định dữ liệu cần thu thập: Người dùng xác định cụ thể dữ liệu mà họ muốn thu thập từ trang web, ví dụ: giá sản phẩm, mô tả sản phẩm, thông tin liên hệ, vv.
- Tải trang web: Web scraper tải trang web mục tiêu theo địa chỉ URL được cung cấp.
- Phân tích HTML: Web scraper phân tích HTML của trang web để tìm kiếm và xác định cấu trúc của dữ liệu cần thu thập.
- Trích xuất dữ liệu: Dữ liệu được trích xuất từ trang web dựa trên cấu trúc HTML, ví dụ: thông qua các thẻ, lớp, id hoặc các mẫu cú pháp.
- Lưu trữ dữ liệu: Dữ liệu được thu thập sau đó có thể được lưu trữ trong cơ sở dữ liệu, tệp tin hoặc hệ thống lưu trữ khác để sử dụng, phân tích hoặc hiển thị sau này.
Các web scraper có thể tự động hóa các hoạt động này để thu thập dữ liệu từ nhiều trang web khác nhau một cách hiệu quả và liên tục. Tuy nhiên, việc sử dụng web scraper cần phải tuân thủ các quy định về bản quyền, chính sách sử dụng của trang web cũng như các quy định pháp luật liên quan đến việc thu thập dữ liệu từ internet.
Tất cả Web Scraping đều xấu là đúng hay sai?
Quá trình triển khai Web Scraping không phải lúc nào cũng xấu! Nhưng việc sử dụng Web Scraping có thể gây ra một số vấn đề liên quan đến luật pháp, đạo đức và chính sách của trang web. Dưới đây là một số điểm cần xem xét:

- Luật bản quyền và chính sách sử dụng: Một số trang web có các điều khoản và điều kiện cụ thể về việc sử dụng dữ liệu của họ. Nến bạn thực hiện Web Scraping mà không có sự cho phép có thể vi phạm luật bản quyền và chính sách của trang web đó.
- Ảnh hưởng đến trang web nguồn: Các hoạt động Web Scraping có thể tạo ra tải trọng lớn đối với trang web nguồn, đặc biệt nếu việc truy cập diễn ra liên tục hoặc người dùng đưa ra lượng lớn các yêu cầu cùng một lúc.
- Bảo mật thông tin cá nhân: Việc thu thập dữ liệu một cách không đúng cách hoặc không tuân thủ các quy định bảo vệ thông tin cá nhân có thể gây ra rủi ro về quyền riêng tư và an ninh thông tin.
Trên thực tế vẫn có nhiều trường hợp sử dụng Web Scraping là đúng và hợp lý. Chẳng hạn như nghiên cứu thị trường, phân tích cạnh tranh, thu thập thông tin công cộng và giám sát dữ liệu. Trong những trường hợp này, việc tuân thủ những quy định và chính sách liên quan cực kỳ quan trọng.
Tính ứng dụng hợp pháp của Web Scraping
Web Scraping có thể được ứng dụng trong nhiều lĩnh vực khác nhau, bao gồm:
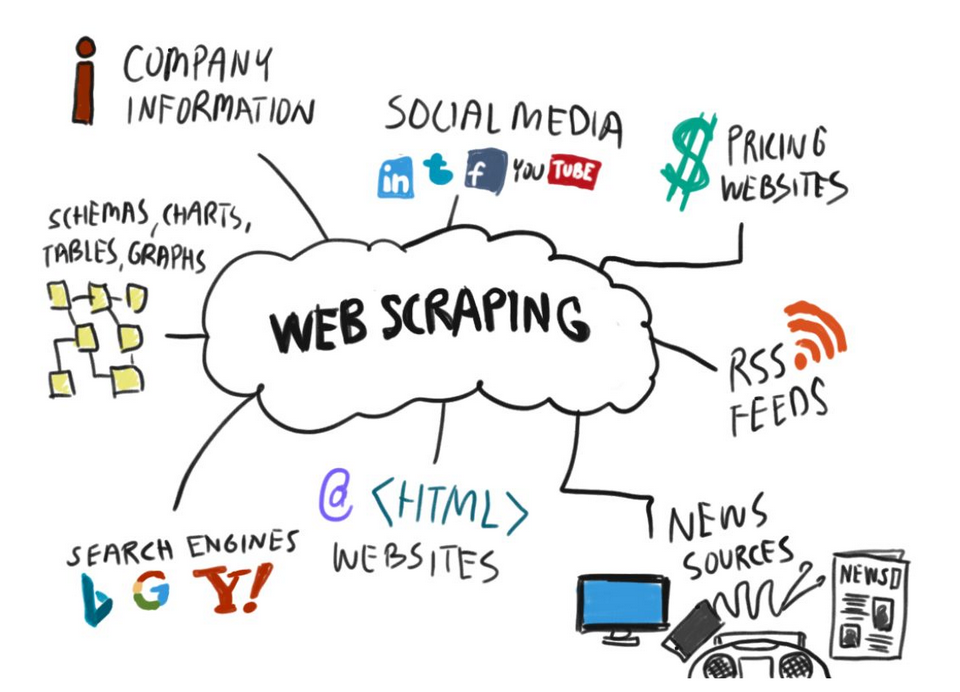
- Nghiên cứu thị trường và kinh doanh: Sử dụng dữ liệu thu thập từ các trang web thương mại điện tử để phân tích xu hướng mua sắm, đánh giá cạnh tranh và xác định giá cả.
- Phân tích dữ liệu và dự báo: Sử dụng tính năng quét dữ liệu web để phân tích và dự đoán xu hướng thị trường, dự báo kết quả kinh doanh và tìm kiếm thông tin cần thiết để quyết định.
- Giám sát sản phẩm và dịch vụ: Theo dõi và cập nhật thông tin về sản phẩm, dịch vụ và các thông tin liên quan từ các trang web.
- Nghiên cứu và phân tích dữ liệu: Thu thập dữ liệu từ các trang web, diễn đàn, blog để phân tích ý kiến, suy nghĩ và tình hình lược đồ phản hồi xã hội đối với một sự kiện hoặc chủ đề cụ các.
- Thương mại điện tử và tiếp thị: Thu thập dữ liệu về giá cả, sản phẩm và thông tin khuyến mãi từ các trang web thương mại để phục vụ cho công việc nghiên cứu thị trường và tiếp thị.
- Nghiên cứu khoa học: Thu thập dữ liệu từ các nguồn trực tuyến để phục vụ cho nghiên cứu khoa học và phân tích dữ liệu.
Phân tích các mặt trái của Web Scraping
Mặt trái của Web Scraping có thể bao gồm một số vấn đề và thách thức sau:

- Vi phạm luật bản quyền: Việc thu thập dữ liệu từ trang web mà không có sự cho phép có thể vi phạm quyền sở hữu trí tuệ và luật bản quyền của trang web đó.
- Gây ra tải trọng lớn: Web Scraping có thể tạo ra lưu lượng truy cập lớn đối với trang web nguồn và gây mất ổn định hoặc nguy cơ bị chặn truy cập từ phía trang web đó.
- Bảo mật thông tin cá nhân: Việc thu thập thông tin từ trang web mà không tuân thủ các quy định bảo vệ thông tin cá nhân có thể dẫn đến rủi ro về quyền riêng tư và an ninh thông tin.
- Pháp lý và chính sách: Việc Web Scraping không tuân thủ các quy định và chính sách của trang web có thể vi phạm pháp luật và gây ra hậu quả pháp lý.
- Ép buộc cạnh tranh không lành mạnh: Việc sử dụng dữ liệu thu thập từ Web Scraping để cạnh tranh không lành mạnh có thể dẫn đến các hậu quả tiêu cực cho thị trường và doanh nghiệp khác.

Ví dụ minh họa
Để tìm hiểu thêm về mặt tiêu cực khi dùng Web Scraping, bạn có thể theo dõi ví dụ khi một công ty sử dụng Web Scraping để lấy trộm dữ liệu của đối thủ cạnh tranh mà không có sự cho phép.
Chẳng hạn, một công ty A sử dụng Web Scraping để tự động thu thập thông tin từ trang web của công ty B. Trong đó bao gồm thông tin sản phẩm, giá cả, thông tin khách hàng hoặc các dữ liệu cạnh tranh khác. Công ty A có thể sử dụng dữ liệu này với mục đích xây dựng chiến lược cạnh tranh không lành mạnh. Hoặc thậm chí là họ sẽ sao chép các sản phẩm, dịch vụ của công ty B một cách không trung thực.

Trong trường hợp này, việc sử dụng Web Scraping không chỉ vi phạm quyền sở hữu trí tuệ và luật bản quyền của công ty B. Mà nó còn có thể dẫn đến các hậu quả pháp lý và hậu quả về uy tín doanh nghiệp. Vấn đề gây ảnh hưởng lớn đến môi trường kinh doanh chung.
Tạm kết
Những chia sẻ trong bài viết trên giới thiệu những thông tin cơ bản về Web Scraping. Công cụ sở hữu nhiều tính năng đặc biệt trong việc khai thác dữ liệu. Tuy nhiên, người dùng nên lưu ý về cách sử dụng Web Scraping hiệu quả và tránh vi phạm pháp luật.
Xem thêm:
- Chi tiết cách tải Zoom và đăng ký tài khoản Zoom trên máy tính hỗ trợ học và họp trực tuyến
- Những cách tải ảnh trên Instagram chất lượng cao nhanh nhất có thể bạn chưa biết
Tại FPT Shop cung cấp nhiều mẫu máy tính bảng chất lượng với giá cả phải chăng. Để lựa chọn các sản phẩm tốt thì bạn có thể theo dõi trang chủ hoặc ghé thăm cửa hàng trực tiếp.
:quality(75)/2023_11_17_638358230770929367_cong-nghe-gentle-wind-thumb.jpg)
:quality(75)/2023_11_17_638358426577705270_may-lanh-panasonic-ra-mat-nam-2023-anh-bia-1.jpg)
:quality(75)/2023_11_17_638358567151011058_cong-nghe-cap-dong-mem-tren-tu-lanh-shark-la-gi.jpg)
:quality(75)/2023_11_17_638358557180946260_b21-bua-rs.jpg)
:quality(75)/2023_11_17_638358542944089533_b20-1rs.jpg)
:quality(75)/2023_11_17_638358464201320361_cong-nghe-lam-lanh-nhanh-fast-cooling.png)