:quality(75)/Vision_Language_Models_cover_a4c4f98653.png)
Vision Language Models là gì? Tìm hiểu cách mô hình AI đọc ảnh và phản hồi bằng văn bản
Khi bạn chụp một bức ảnh và mong muốn hệ thống có thể mô tả, phân tích hoặc thậm chí trả lời câu hỏi liên quan đến nội dung trong ảnh, đó chính là lúc công nghệ AI đa phương thức phát huy vai trò. Khả năng kết hợp giữa thị giác và ngôn ngữ giúp AI tiến gần hơn đến cách con người tiếp nhận thông tin. Đó cũng là lý do Vision Language Models ngày càng được quan tâm trong nhiều lĩnh vực công nghệ.
Vision Language Models là gì?
Vision Language Models là các mô hình trí tuệ nhân tạo có khả năng xử lý đồng thời dữ liệu hình ảnh và ngôn ngữ trong cùng một kiến trúc, từ đó tạo ra sự liên kết chặt chẽ giữa thông tin thị giác và ngữ nghĩa văn bản thay vì tách rời như trước đây. Khi một hệ thống vừa phân tích nội dung trong ảnh vừa hiểu cách diễn đạt bằng ngôn ngữ, khả năng phản hồi trở nên linh hoạt hơn và gần với tư duy con người hơn, đặc biệt trong các tình huống cần suy luận từ ngữ cảnh đa dạng.
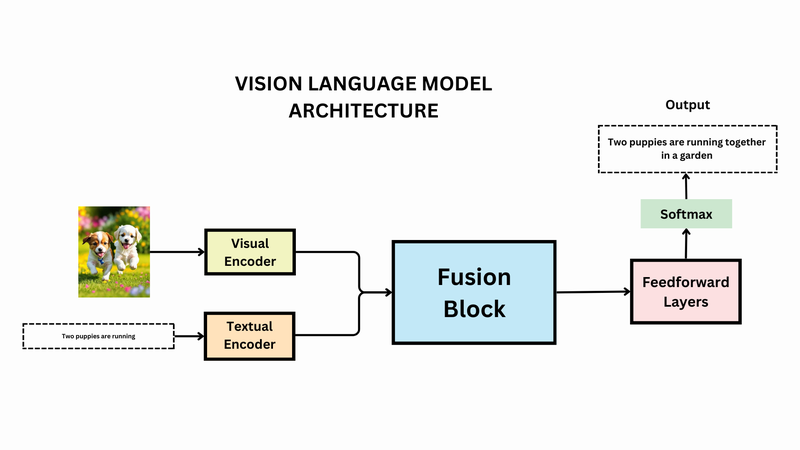
Thay vì xây dựng hai pipeline riêng biệt cho hình ảnh và văn bản rồi ghép nối ở bước cuối, Vision Language Models triển khai cách tiếp cận hợp nhất ngay từ đầu, nhờ đó quá trình học trở nên đồng bộ hơn và giảm sai lệch khi chuyển đổi giữa hai loại dữ liệu. Cách tổ chức này giúp mô hình không chỉ nhận diện đối tượng mà còn hiểu mối quan hệ giữa các thành phần trong ảnh, đồng thời diễn đạt lại bằng ngôn ngữ tự nhiên một cách có logic.
Các mô hình nổi bật hiện nay gồm CLIP của OpenAI, BLIP, và GPT-4V, đại diện cho khả năng liên kết hình ảnh và ngôn ngữ với hiệu quả cao trong nhiều ứng dụng thực tế.

Cơ chế hoạt động của Vision Language Models
Kiến trúc mã hóa hình ảnh và ngôn ngữ trong cùng một hệ thống
Vision Language Models vận hành dựa trên việc chuyển đổi hình ảnh và văn bản thành các dạng biểu diễn số, sau đó đưa chúng vào một không gian ngữ nghĩa chung để mô hình có thể thiết lập mối liên hệ trực tiếp giữa hai loại dữ liệu. Trong quá trình này, hình ảnh được phân tích thành các đặc trưng như hình dạng, màu sắc và bố cục thông qua vision encoder, trong khi văn bản được mã hóa thành các vector mang ý nghĩa ngữ cảnh nhờ language encoder, từ đó hệ thống có thể so sánh và liên kết thông tin giữa những gì nhìn thấy với cách diễn đạt bằng ngôn ngữ.
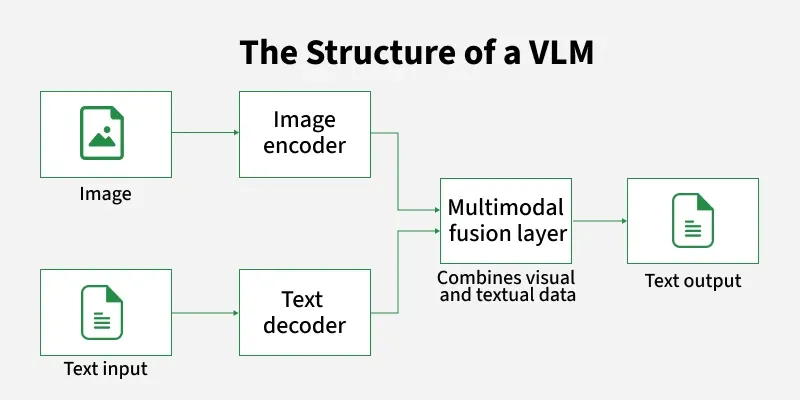
Điểm quan trọng nằm ở việc hai luồng dữ liệu không còn tồn tại tách biệt mà được học đồng thời trong cùng một kiến trúc, vì vậy mô hình có khả năng hiểu nội dung ở mức sâu hơn thay vì chỉ dừng lại ở nhận diện hoặc phân tích riêng lẻ từng loại dữ liệu như các hệ thống truyền thống.
Cơ chế học liên kết ngữ nghĩa từ dữ liệu đa phương thức
Sau khi được thiết kế kiến trúc phù hợp, Vision Language Models tiếp tục được huấn luyện trên tập dữ liệu lớn gồm các cặp hình ảnh và mô tả, nhờ đó mô hình dần học được cách con người liên kết thông tin thị giác với ngôn ngữ trong nhiều ngữ cảnh khác nhau. Quá trình này giúp hệ thống không chỉ nhận diện đối tượng mà còn hiểu được hành động, bối cảnh và mối quan hệ giữa các thành phần trong ảnh.
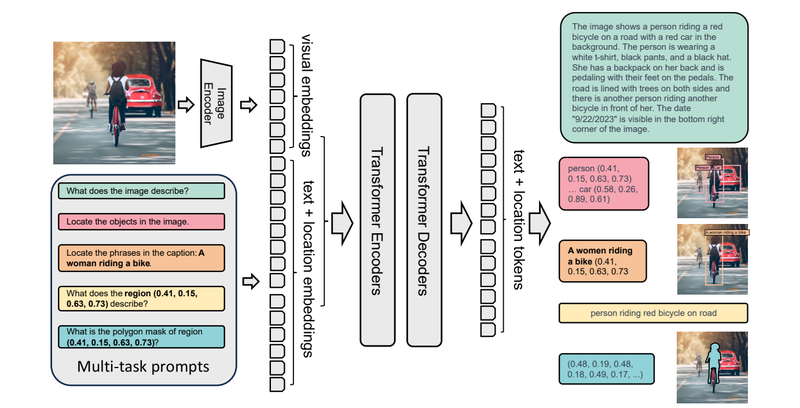
Khi áp dụng vào thực tế, mô hình có thể mô tả nội dung hình ảnh, trả lời câu hỏi hoặc đưa ra nhận định dựa trên ngữ cảnh, bởi vì toàn bộ mối liên hệ giữa hình ảnh và ngôn ngữ đã được tối ưu trong quá trình huấn luyện, từ đó giúp phản hồi trở nên tự nhiên và chính xác hơn trong các tình huống đa phương thức.
So sánh Vision Language Models với các mô hình khác
Khi đặt Vision Language Models trong tương quan với các hướng tiếp cận AI trước đó sẽ giúp thấy được rõ sự khác biệt về cách xử lý dữ liệu cũng như mức độ hiểu ngữ cảnh, đặc biệt khi so sánh với các mô hình chỉ tập trung vào văn bản hoặc hình ảnh riêng lẻ. Từ đó, ta có thể thấy rõ vì sao cách tiếp cận đa phương thức đang dần trở thành xu hướng chủ đạo.
| Tiêu chí | Large Language Models (LLM) | Computer Vision | Vision Language Models (VLM) |
|---|---|---|---|
| Loại dữ liệu xử lý | Văn bản | Hình ảnh | Hình ảnh + văn bản |
| Cách tiếp cận | Xử lý ngôn ngữ tự nhiên, tập trung vào suy luận từ chữ | Nhận diện, phân loại và phát hiện đối tượng trong ảnh | Kết hợp xử lý thị giác và ngôn ngữ trong cùng một mô hình |
| Khả năng hiểu ngữ cảnh | Tốt với văn bản, nhưng không hiểu trực tiếp hình ảnh | Hiểu hạn chế, chủ yếu dừng ở mức nhận diện | Hiểu ngữ cảnh đa phương thức, liên kết hình ảnh với ý nghĩa |
| Xử lý hình ảnh | Phải thông qua bước chuyển đổi sang văn bản | Xử lý trực tiếp | Xử lý trực tiếp trong cùng hệ thống |
| Khả năng diễn đạt bằng ngôn ngữ | Tốt | Hạn chế, cần hệ thống bổ trợ | Tự nhiên, mô tả và giải thích nội dung ảnh |
| Mức độ tích hợp | Đơn nhiệm (text-only) | Đơn nhiệm (vision-only) | Đa phương thức (multimodal) |
| Hạn chế chính | Không hiểu trực tiếp hình ảnh | Không hiểu sâu về ngữ nghĩa và bối cảnh | Yêu cầu dữ liệu lớn và phần cứng mạnh |
Ứng dụng thực tế của Vision Language Models trong hệ sinh thái AI
Chatbot có khả năng hiểu hình ảnh
Các chatbot tích hợp Vision Language Models có thể tiếp nhận hình ảnh từ người dùng và đưa ra phản hồi dựa trên nội dung trực quan, từ việc nhận diện lỗi thiết bị cho đến hướng dẫn thao tác, nhờ đó trải nghiệm hỗ trợ trở nên trực tiếp và dễ hiểu hơn so với việc mô tả bằng lời.

Tìm kiếm bằng hình ảnh và ngữ nghĩa
Trong thương mại điện tử và tìm kiếm thông tin, người dùng ngày càng có xu hướng sử dụng hình ảnh thay cho từ khóa, vì cách này nhanh hơn và phản ánh đúng nhu cầu hơn. Vision Language Models giúp hệ thống hiểu nội dung hình ảnh, sau đó liên kết với dữ liệu văn bản để trả về kết quả phù hợp với ngữ cảnh tìm kiếm.
Sáng tạo nội dung đa phương tiện
Trong lĩnh vực marketing và truyền thông, Vision Language Models hỗ trợ tạo mô tả sản phẩm, viết caption hoặc kết hợp hình ảnh với nội dung văn bản một cách tự động, giúp rút ngắn thời gian sản xuất nội dung trong khi vẫn đảm bảo tính nhất quán về thông điệp.
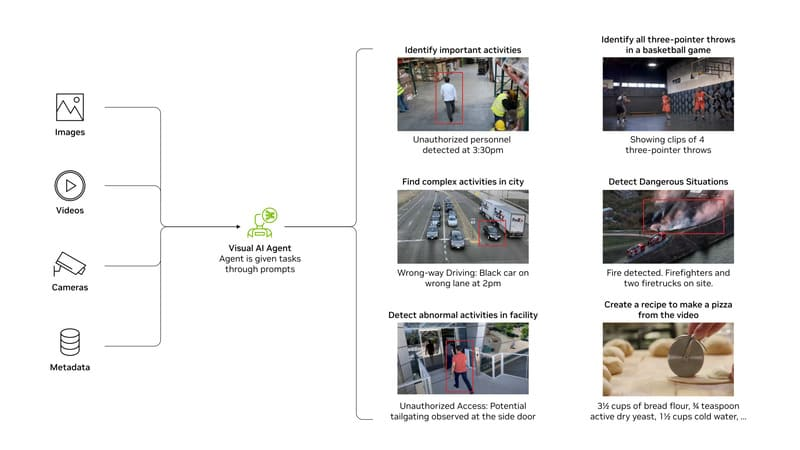
Hỗ trợ phân tích dữ liệu trực quan
Ở các lĩnh vực chuyên sâu như y tế hoặc giáo dục, khả năng chuyển đổi hình ảnh thành thông tin dễ hiểu giúp người dùng tiếp cận dữ liệu nhanh hơn, đồng thời giảm phụ thuộc vào chuyên gia trong những tác vụ cơ bản.
Lợi ích và thách thức của Vision Language Models
Việc kết hợp hình ảnh và ngôn ngữ trong cùng một mô hình giúp nâng cao trải nghiệm người dùng khi tương tác với AI, bởi người dùng có thể cung cấp thông tin dưới nhiều dạng khác nhau mà vẫn nhận được phản hồi chính xác và phù hợp ngữ cảnh. Khi hệ thống hiểu được cả nội dung trực quan lẫn cách diễn đạt bằng chữ, quá trình giao tiếp trở nên tự nhiên hơn và giảm đáng kể sự phụ thuộc vào thao tác nhập liệu truyền thống.
Tuy nhiên, để đạt được hiệu quả này, Vision Language Models cần lượng dữ liệu huấn luyện lớn và đa dạng, đồng thời đòi hỏi phần cứng đủ mạnh để xử lý khối lượng tính toán phức tạp, vì vậy việc triển khai trong thực tế thường gắn liền với chi phí cao và yêu cầu kỹ thuật khắt khe hơn so với các mô hình AI đơn nhiệm.
Tạm kết
Vision Language Models mang đến cách tiếp cận mới khi kết hợp khả năng xử lý hình ảnh và ngôn ngữ trong cùng một hệ thống, giúp AI hiểu dữ liệu trực quan một cách toàn diện hơn, qua đó cải thiện trải nghiệm tìm kiếm, tăng độ chính xác trong phân tích nội dung và hỗ trợ tự động hóa nhiều tác vụ phức tạp. Vì vậy, Vision Language Models đã và đang trở thành nền tảng quan trọng để khai thác AI hiệu quả và chủ động hơn trong môi trường số.
Nếu bạn thường xuyên làm việc với các công cụ AI, một chiếc laptop AI sẽ giúp xử lý nhanh hơn các tác vụ liên quan đến hình ảnh và dữ liệu đa phương thức. FPT Shop cung cấp nhiều dòng laptop AI chính hãng với hiệu năng ổn định và khả năng tối ưu cho công việc hiện đại. Hãy ghé cửa hàng gần nhất hoặc truy cập website FPT Shop để chọn cho mình thiết bị phù hợp.
Xem thêm:
:quality(75)/mcp_la_gi_71f309adbe.png)
:quality(75)/microsoft_ai_ra_mat_cac_mo_hinh_ai_tu_phat_trien_dau_tien_304f175346.jpg)
:quality(75)/palm_2_llm_la_gi_1_4990da88d5.jpg)
:quality(75)/google_gemma_3_2_1e45b5afeb.jpg)
:quality(75)/figma_ra_mat_weave_ung_dung_giup_ket_hop_nhieu_mo_hinh_ai_va_cong_cu_chinh_sua_f1243e8e39.jpg)
:quality(75)/google_ra_mat_gemini_25_pro_phien_ban_moi_cho_nguoi_dung_viet_1_5434209bd6.jpg)